背景
市场回归保障,重疾赔付恶化,互联网渠道强势入场。。。在种种背景之下,国内寿险业不再仅仅是关注销售,也逐渐加深对于业务品质的分析管控,如何在控制风险的前提下精准定价提升产品竞争力,成为业内公司的研究重点。经验分析作为这其中的关键一环,也越来越受到重视,有越来越多的人员投入到相关的工作中。作为在这一领域从业6年的一员,分享一些经验分析的思路和心得,篇幅有限一些涉及细节内容就不详述了。
本文更多面向刚入坑和想入坑的小伙伴,为了便于理解我把经验分析比作做菜,共分为五个部分,简要提纲如下。
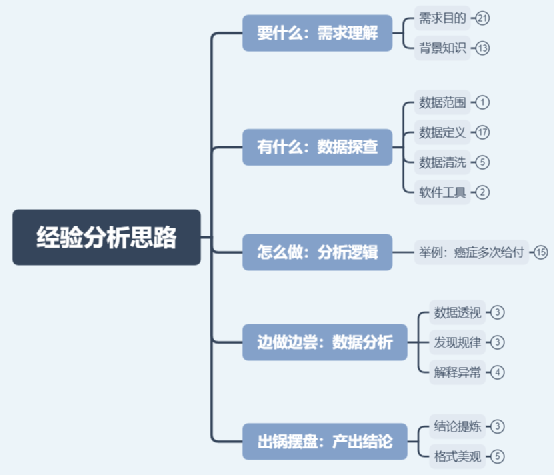
三、怎么做:分析逻辑
这部分主要是指新菜谱的研发,常规的发生率、退保率和费用分析相信各公司都有很多现成的模板套路。这两年保障型市场竞争越来越激烈,倒逼产品责任创新不断发力,对经验分析的挑战是如何根据现有数据的拼接组合,产出对创新责任的成本估计。思路需要提前梳理,搞清楚前两步的要什么和有什么之后,构建出一个分析模型来,多数情况是一种多状态转移模型。举例说明:
癌症多次给付是这两年的一个创新责任,如何计算二次和三次癌症发生率就是我们要研发的新菜谱。根据责任特点,可知求解首先需要了解两方面信息:
1、客户发生首次癌症的信息,且癌症后可持续观察直至客户身故;
重疾和身故保额不相等,或重疾后身故责任不终止的提前给付重疾或防癌产品,可以提供这方面信息。
2、客户首次癌症后,癌症的持续治疗信息,需要包含较明确的病种信息;
保证续保的0免赔医疗险产品可以提供这方面信息,但需要赔案核赔描述有较详细的文字或病种记录,可以清洗出具体癌症部位。
其次,数据齐备后需要根据责任构建首次癌症后的多状态转移模型,可作适当合理简化,例如忽略首次癌症后的退保,如下图:
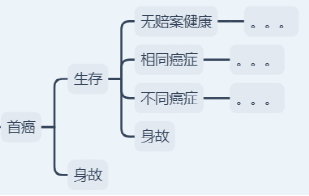
最后,区分首癌后各年度计算每条状态转移路径的发生概率,形成精算常用的人口脱退模型,模拟癌症二次、三次赔付的成本。其中相同或不同癌症的信息是用于近似癌症的复发或转移。
四、边做边尝:数据分析
食材加工的火候,料理调配的口味,都需要不断甚至反复尝试才能达到最佳。数据分析本身也是个迭代的过程,数据背后的真相是需要挖掘出来的。按照顺序大致可以分为下面三个步骤,但这三个步骤往往不是按顺序走一轮结束的,需要反复迭代分析。
数据透视:
这是基本操作规定动作,适当有效地利用模板和一些自动化工具,能显著提升处理速度和效率。数据透视时要注意避免干扰值,最常见的就是因数据量较小而带来的结果波动。那如何判断数据量是否充足呢?以发生率为例,笔者建议通过赔案数来简单判断,利用二项分布特性和置信区间算法,可简单推导出发生率的波动幅度约为2/x^0.5,x为赔案数。即如果样本观察到赔案数有100件,那在95%置信度下样本发生率约在真实发生率的正负20%区间内。
发现规律:
简单来说就是看图说话,总结自变量与因变量之间的因果关系,比较常见的例如死亡率随年龄增长呈现U字型,重疾发生率有逐年恶化的趋势,退保率会随保单年度增加而下降等。但真实世界的变量间关系总是复杂的,有交叉影响的,如何排除其他因素影响,进行单变量分析显得尤为重要。最常见的传统方式是发生率A/E分析,用于排除性别和年龄两个关键因素研究其他因素对发生率的影响。当然,进行回归建模是更好的选择,目前行业比较常用的是逻辑回归,属于广义线性回归的一种,相比随机森林等分类模型有更好的解释性。有兴趣的小伙伴可以查阅其他文章,这里不展开讲了。
解释异常:
分析结果的对比印证非常重要,能帮助我们更好的判断结果的合理性。而对不合理结果的解释,最能体现经验丰富的数据分析人员的能力。刚入行的小白总是惊讶于为什么我的boss能一眼看出我的数据做错了,甚至哪里错了,我想说你现在踩的坑你的boss早就踩过了。。。说的绝对一点,在数据体量质量有保证的前提下,基于大数法则,出现异常结果的地方一定存在计算错误或者可解释的业务逻辑。而挖掘这些异常点背后的业务逻辑,形成因果关系分析,往往就是数据分析的价值所在。比如首年退保率显著偏高的产品背后原因是自保件比例过大;又比如前3个保单年度发生率通常呈V字型,是因为首年逆选择效力较强,次年核保选择效力较强,第三年又存在不可抗辩期影响。
五、出锅摆盘:结论输出
好的菜品需要色香味俱全,精致小炒相比大锅菜在卖相上对于客户食欲的提升也非常重要。数据分析报告的输出对象通常都是领导、客户,数据的可视化分析结论的展示也是一门学问。笔者主要提出下面两点。
结论提炼:
数据分析的结论或报告一定不是数据报表的平铺堆砌。有个误区是我要展示所有标签维度下的指标分析结果,要面面俱到。但这等于是把海里捞针变成湖里捞针,决策者要的是你把针捞出来递到他手上。大量的数据报表可以作为附表备查,重要的是提炼与需求目的密切相关或存在潜在风险的核心结论。要做到这一点,我们的第一步需求理解一定要到位,以数据分析作为解决方案,传达解释论证分析结论,在报告中形成清晰的故事线。一个简单的方式是提炼精简干练的短句形成小标题,将小标题前后串联后检查整体报告逻辑是否通顺,信息是否有冗余,而后不断梳理调整。
格式美观:
笔者认为做数据分析最好稍稍带点强迫症,我的EXCEL底稿一直有固定的字体和字号,面对杂乱无章的底稿通常内心是崩溃的,甚至要先调格式我才能正常思考。。。当然这是锦上添花,不能本末倒置。
对分析者来讲,格式美观不仅指你的PPT做的多好看,更重要的是一种工作习惯,你是否有规范的文档命名规则,你是否统一了报告图表格式,你是否做了详细的口径注释等。
对阅读者来讲,增加阅读兴趣,降低阅读难度,能更准确地理解分析结论。
对传承者来讲,极大提升工作底稿的复用性,好的工作底稿甚至不需要讲解或操作指引就可以直接交接复用。
结语
数据是一笔宝贵的财富,我们要更好地利用它。
欢迎更多小伙伴入坑。




 中再寿险视频号
中再寿险视频号 中再寿险公众号
中再寿险公众号